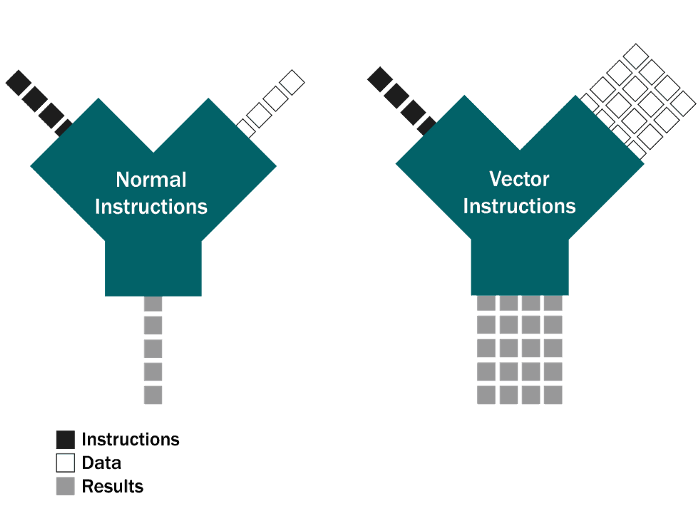
Vectorized Queries
Vectorized execution operates on batches of rows at a time instead of individual rows.
It allows queries to be sped up by reducing the number of method calls, improving cache efficiency, and potentially enabling CPU SIMD instructions.
Scope
Supported Vectorized Query Types
As of Druid 0.20.2, the following query types can be vectorized:
- GroupBy
- Timeseries
Vectorization has a few important requirements:
- Query-level filters must either run on bitmap indexes or offer vectorized row matchers.
- Supported filters include selector, bound, in, like, regex, search, and, or, and not.
- Filters in filtered aggregators must offer vectorized row matchers.
- Aggregators must offer vectorized implementations, including count, numeric sum/min/max, any-value aggregators, hyperUnique, filtered, approxHistogram, approxHistogramFold, and fixedBucketsHistogram.
- Virtual columns must offer vectorized implementations.
- GroupBy dimension specs must be default specs, without extraction functions, filtered dimension specs, or multi-value dimensions.
- Timeseries queries cannot use descending order.
- Only immutable segments and table datasources are supported.
Unsupported Query Types
As of Druid 0.20.2, these query types cannot be vectorized:
- TopN
- Scan
- Select
- Search
Vectorization Parameters
| Property | Default | Description |
|---|---|---|
vectorize | true | Enables or disables vectorized query execution. |
vectorSize | 512 | Sets the row batching size for a query and overrides druid.query.default.context.vectorSize when set. |
vectorizeVirtualColumns | false | Controls vectorized processing for virtual columns. Values are false, true, and force. |
How To Enable Vectorization
Set vectorization defaults in common config:
druid.query.default.context.vectorize=true
druid.query.default.context.vectorSize=1024
druid.query.default.context.vectorizeVirtualColumns=trueOr pass vectorization parameters in query context:
{
"context": {
"vectorize": true,
"vectorSize": 512,
"vectorizeVirtualColumns": false
}
}